В прошлой
статье рассмотрели общую схему создания и проектирования системы для алгоритмической торговли на бирже. Рассмотрим более подробно работу каждого модуля.
Как получить исторические данные для работы мы уже знаем. Сейчас рассмотрим необходимый минимальный функционал для своего терминала визуализации.
Ниже буду приводить скриншоты моей последней версии «Анализатора», более раннюю версию можно скачать с серверов S#. Просто опишем, что из себя представляет система визуализации стратегий.
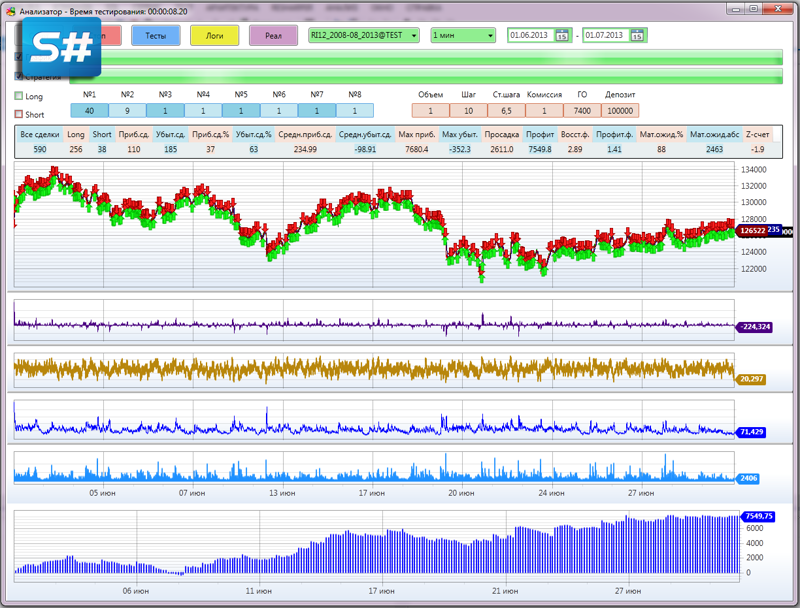
Задаем диапазон тестирования, таймфрейм и тестируемый инструмент. Как дополнительно, но не обязательно можно задать комиссию, начальный депозит и др. настраиваемые параметры.
Строим свечной график, также выводим индикаторы. Снизу строим график Эквити. В данном примере для оценки стратегии я использую свой расчет Профита. В стандартной версии графика PnL от S# используется немного другой вариант, более приспособленный для торговли в реальном времени с расчетом вариационной маржи.
Выводим сделки на график в виде стрелок. Зеленая стрелка покупка, красная продажа. Это стандартная функция. Прикрутить к коду не сложно, главное округлить время сделки до времени свечки, а то она может выставиться некорректно.
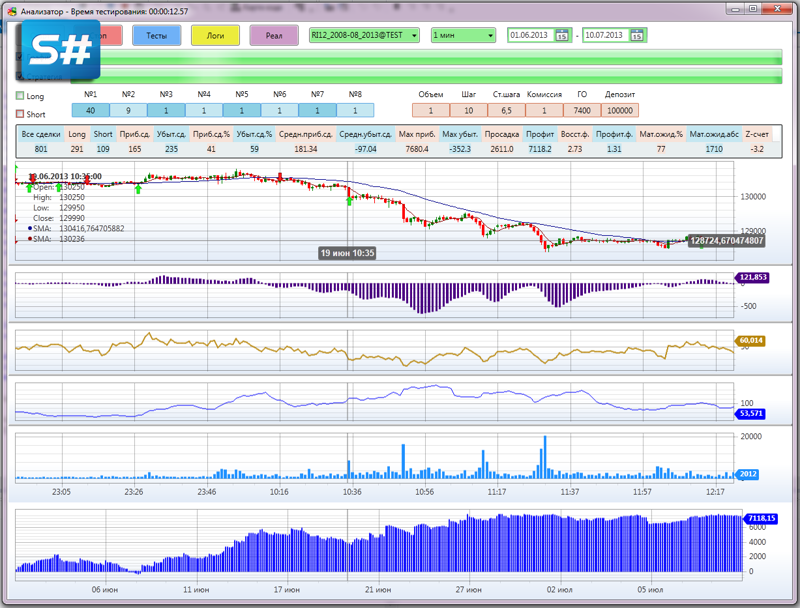
Что нам еще нужно? Не плохо бы знать, что и в какой последовательности делала наша стратегия. Нам нужно Логирование! В стандартных версиях полно разных видов окон логирования, но я как всегда не ищу легких путей и сделал свое логирование на базе ListView из WPF C#.
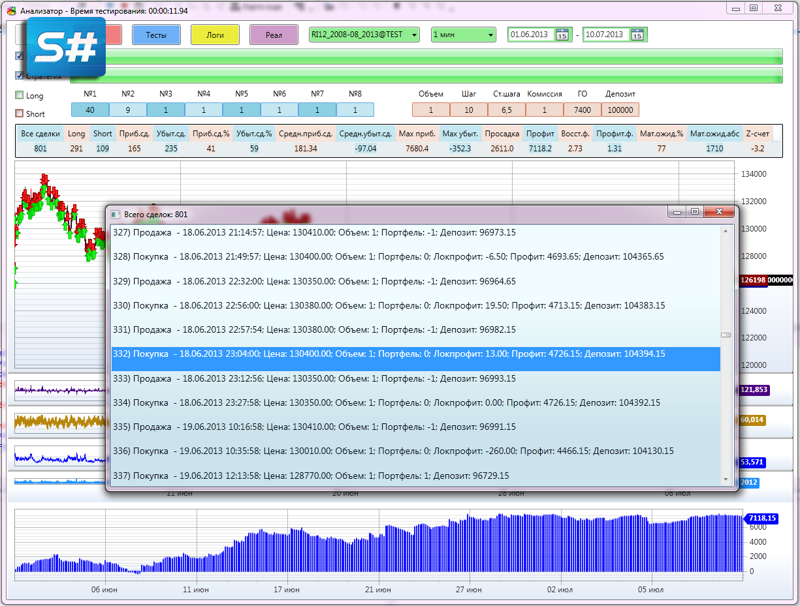
Для удобства вывел на экран кнопки для запуска результатов тестирования и таблицу с расчетом статистических данных стратегии.
Статистика Очень важно перед запуском стратегии для реальной торговли на бирже проверить ее на работоспособность – протестировать. Как нам узнать какая стратегия хорошая, а какая плохая? Оказывается итоговая прибыль в конце тестирования не единственно важный показатель нашего алгоритма. Для полной картины нам нужно изучить статистические показатели нашей стратегии.
Основные формулы для расчета показателей стратегии:
1. Profit factor (PF)Рассчитывается как отношение за определённый период суммы всех прибыльных сделок к сумме всех убыточных с положительным знаком. Большее значение соответствует меньшей вероятности разорения.
Profit Factor = [Сумма прибылей всех прибыльных сделок] / [Сумма прибылей всех убыточных сделок]
2. Maximum Intraday Drawdown (MIDD)Максимально Нарастающий Убыток (MIDD — Maximum Intraday Drawdown). Он обозначает самую большую финансовую яму, в которую попадала наша система.
Максимальный нарастающий убыток – это глубина максимальной просадки за период.
3. Вероятность выигрыша %W (P)%W(P) вероятность выигрыша (отношение количества выигрышных сделок к общему их количеству).
* вероятность выигрыша > 0,5.
4. Математическое ожидание M[X]Математическое ожидание — понятие среднего значения случайной величины в теории вероятностей. В зарубежной литературе обозначается через Е[X], в русской M[X]. В статистике часто используют обозначение μ.
Наиболее распространенные варианты расчета:
1) M[X] Математическое ожидание = вероятность выигрыша * средняя величина выигрыша + вероятность проигрыша * средняя величина проигрыша (в качестве результата прирост на 1 сделку в абсолютных величинах)
2) M[X] Математическое ожидание (1+( средняя величина выигрыша / средняя величина проигрыша))* вероятность выигрыша -1 (в качестве результата вероятность в % получения прибыли за период)
* M[X] > 0,6 верно для варианта 2.
5. Фактор восстановления (RF)RF (фактор восстановления, restoration factor) = отношение прибыли за период (Profit) к максимально нарастающему убытку (MIDD) за тот же период.
* при тестировании RF должен быть > 2
6. Стандартное отклонение (σ)Стандартное отклонение σ или SD (sigma) — это широко используемая мера разброса или вариабельности (изменчивости) данных. Стандартное отклонение популяции определяется формулой:
SD= [S(xi-m)2/N]1/2, где m — среднее популяции, N — размер популяции.
7. Z-счетZ-счет позволяет определить эффективность торговой системы одной цифрой, предоставляя более точные результаты при сравнении с другими ТС. Кроме того, положительный либо отрицательный результат Z-счета несет в себе дополнительную информацию об особенностях использования взятой торговой системы.
Собственно, формула вычисления Z-счета имеет вид:
Z-счет = (N*(R — 0.5) — X)/((X*(X — N))/(N -1))^(1/2)
N – общее количество сделок;
X – 2*количество прибыльных сделок*количество убыточных сделок;
R – количество серий (сколько раз после прибыльной сделки шла убыточная и наоборот);
^(1/2) – это квадратный корень.
Для определения Z-счета необходимо иметь данные как минимум по 30 сделкам. Положительный либо отрицательный Z-счет несет в себе дополнительную информацию:
1) Положительный Z-счет означает, что практически после каждой прибыльной сделки следует убыточная, т.е. торговая система склонна к чередованию. И, чем больше число Z-счета, тем чаще происходит чередование. Основываясь на этом, следует после каждой убыточной сделки увеличивать размер лота (т.к. следующая сделка будет прибыльной), а после прибыльной – уменьшать лот.
2) Отрицательный Z-счет означает, что ТС имеет последовательные серии как прибыльных, так и убыточных сделок. Эти данные вырисовывают следующий сценарий – если система склонна к сериям, то после первой убыточной сделки следует прекратить торговлю и войти в рынок снова только после первой прибыльной сделки. Мы пропускаем одну прибыльную сделку, но, при этом, минуем серию убыточных.
Прочая статистическая информация:
8. Общее число сделок.
9. Число прибыльных сделок.
10. Число убыточных сделок.
11. Средняя прибыль от сделки.
12. Средний убыток от сделки.
13. Максимальная прибыль.
14. Максимальный убыток. Есть, конечно, и другие показатели стратегии, но эти наиболее распространенные и информативные.
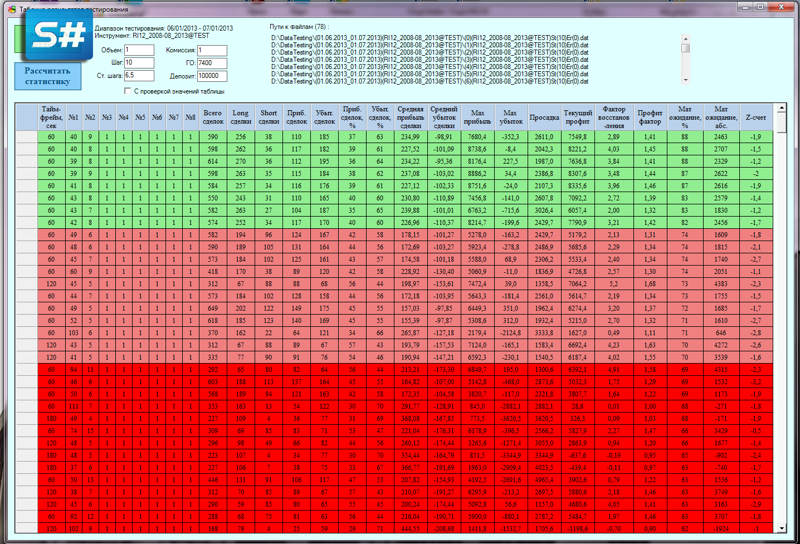
Так выглядит статистика в сводной таблице стратегий:
 Подробнее о тестировании и простой оптимизации
Подробнее о тестировании и простой оптимизации Ранее мы рассмотрели на примерах как можно визуализировать свою стратегию:
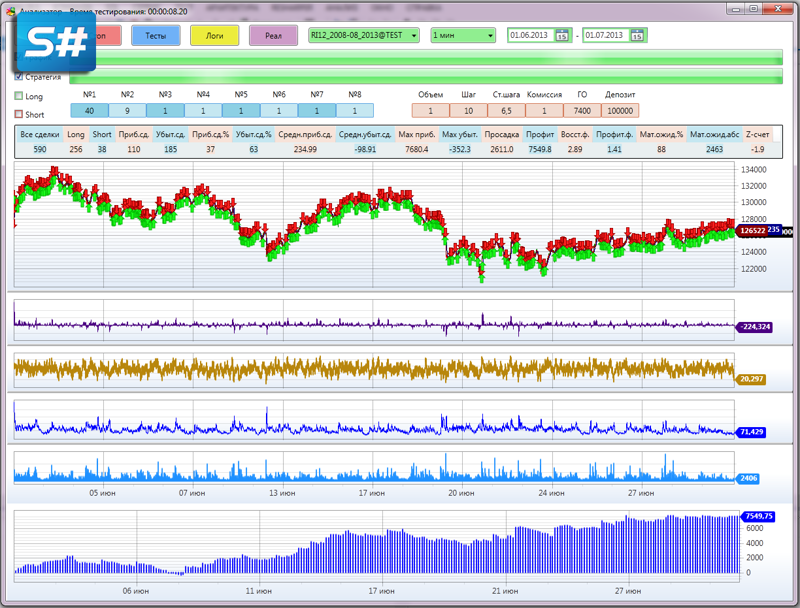
И рассчитать основные ее показатели:
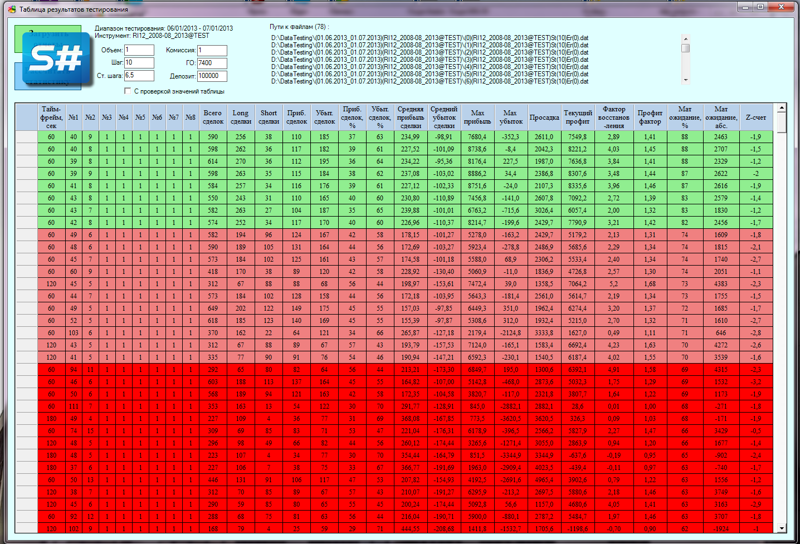
Но все эти приложения имеют графическую оболочку (англ. Graphical user interface, GUI), что сказывается на производительности таких приложений. Для того чтобы тестировать много стратегий и очень быстро нам нужно использовать более производительную архитектуру приложений.
Например, консольные приложения, хотя некоторые профессионалы умудряются обходиться вообще без GUI.
Рассмотрим простое консольное приложение для тестирования стратегий методом перебора.
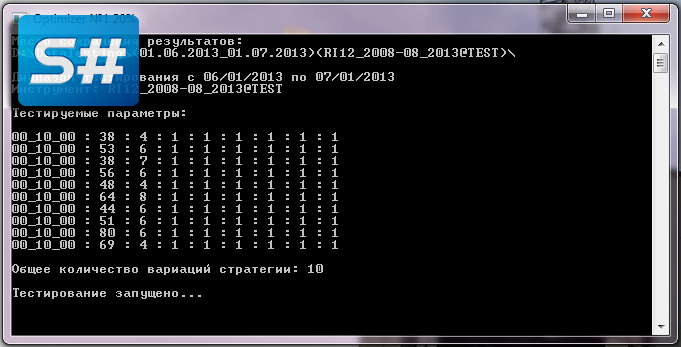
Для тестирования нам совсем не обязательно выводить графики, строить свечки, визуализировать таблицы. Все это можно оставить на заднем плане.
На примере стратегии из двух пересекающихся SMA (Simple Moving Average, простое скользящее среднее) постараемся выбрать лучшие варианты из сочетания длин периодов «короткой» и «длинной» скользящих средних.
Для этого создадим диапазон параметров «длинной» SMA от 20 до 120 и выберем шаг для этого диапазона равным 1. Итоговые данные сохраним в одномерном массиве {20, 21, 22, … ,120}. Аналогично для «короткой» SMA с диапазоном от 5 до 20 с тем же шагом 1 создадим одномерный массив {5, 6, 7, …, 20}.
Теперь сформируем массив всех возможных вариантов стратегий сочетанием значений массива «длинной» и «короткой» SMA. Получим следующий массив всех вариантов параметров нашей стратегии: {{20, 5}, {20, 6}, …, {20, 20}, {21, 5}, …, {120, 19}, {120, 20}}. Итого 1500 вариантов нашей стратегии. Не мало. Поэтому нам так важна скорость тестирования.
В S# есть простые примеры как провести такое тестирование. Я брал исходные параметры наших SMA из массива параметров стратегий и по очереди в цикле их тестировал. В итоге, после каждого теста получал массив []MyTrades в котором хранились данные времени совершения сделок, их направление (Покупка или Продажа), объем сделок (количество контрактов в сделке) и цены сделок за временной период тестирования.
В конце мы получили число массивов с результатами тестирования равное числу всех возможных параметров нашей стратегии. Сохраняем (сериализуем в бинарный файл) все наши параметры и результаты тестирования. Открываем эти файлы в рассмотренном ранее «Анализаторе», рассчитываем по этим данным статистику и получаем итоговую таблицу с результатами тестирования. Сортируем данные, например, по матожиданию и анализируем результаты. При этом можем сразу визуализировать заинтересовавшую нас стратегию.
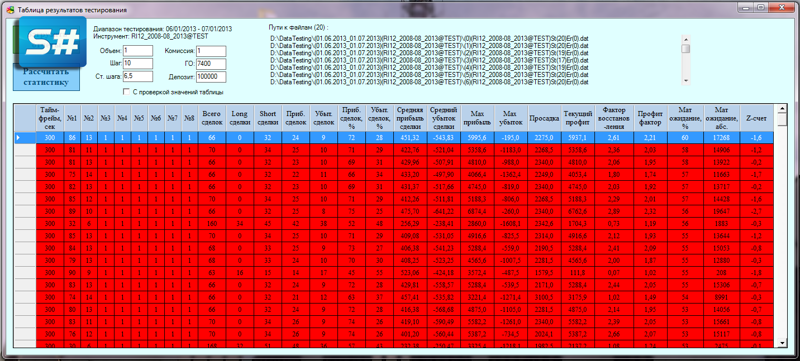
Примерно так проходит тестирование и оптимизация стратегий. Но оптимизация методом перебора зарекомендовала себя как неэффективная и ресурсоемкая при больших объемах данных. В следующей статье мы рассмотрим другие более производительные варианты оптимизации стратегий.
Всем восходящего тренда! С уважением, Bond.
Бонд наш ученик!